")
In today’s world, the stock market is a vital component of the global economy. It is a hub of activity where investors buy and sell stocks, bonds, and other financial instruments, hoping to make a profit. However, predicting the movement of the stock market is not an easy task. The market is volatile and can be affected by a range of factors, including economic conditions, political events, and global trends.
One way to gain a competitive edge in the stock market is through the use of quantitative analysis. Quantitative analysis is a data-driven approach that involves the use of mathematical models, statistical tools, and algorithms to analyze market data and predict future trends. By using quantitative analysis, investors can make informed decisions about when to buy and sell stocks, minimizing risks and maximizing returns.
In this blog post, we will explore the benefits of quantitative analysis for stock market prediction and how it can help investors make more accurate investment decisions. We will delve into the different techniques used in quantitative analysis, such as time series analysis, regression analysis, and machine learning. Additionally, we will examine the challenges associated with quantitative analysis and how to overcome them.
By the end of this post, you will have a better understanding of how quantitative analysis can help you gain a competitive edge in the stock market and make more informed investment decisions. So, whether you are a seasoned investor or just starting, read on to learn more about the power of quantitative analysis in stock market prediction.
THEORIES OF STOCK MARKET PREDICTION
Various theories are available for predicting the stock market prices3. There are two important theories of stock market prediction. One is Efficient Market Hypothesis (EMH) and another one is Random Walk Theory.
Efficient Market Hypothesis (EMH): It expresses that share prices mirror all the accessible data about resources. So it is not possible to outperform the stock market. The efficient market Hypothesis exists in three forms4:
| • | Weak EMH: Only the past data is considered |
| • | Semi-Strong EMH: All public information is utilized |
| • | Strong EMH: Publicly and privately available information is used |
Random walk theory: Random walk theory assumes that it is impossible to predict stock prices as stock prices don’t depend on past stock. It also considers that stock price has great fluctuations so it is infeasible to predict future stock prices.
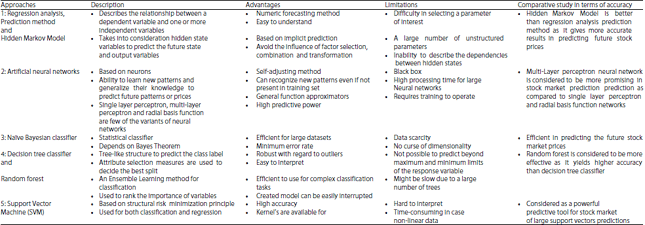
Approaches to stock market prediction: Stock market prediction have two conventional approaches1,2,5 (Table 1):
| • | Technical analysis |
| • | Fundamental analysis |
MACHINE LEARNING ALGORITHMS
Regression analysis and Hidden Markov Model: Regression Analysis is one of the non-linear methods used for stock market prediction. Regression Analysis is based on analyzing the market variables, the regression equation is set among the variables and afterward, this equation is utilized as the predictive model to foresee the adjustments in the number of variables and to predict the dependent variable relationships during the forecast period.
| Table 1: | Approaches to stock market prediction |
 |
|
Hidden Markov Model is also one of the methods used for predicting the stock prices. Hidden Markov Model analyzes the hidden state variables to predict the future output and state variables6.
Artificial neural networks: Artificial neural networks are widely used in stock market prediction. Human neurons are the basic functional unit of artificial neural networks. Neural networks can tackle an issue without an earlier learning of the connection amongst input and output, so these are also called as self-adjusting methods. Special function called as the activation function is used to map the input variables with output variables. In real time, neural networks have a capacity to change its network parameters (synaptic weights)9 neural networks are data-driven models and for real-world prediction problems like stock prediction etc. Data-driven models are considered to be beneficial.
Naïve bayesian classifier: Machine learning is a fast-growing discipline. Machine learning is capable of integrating and acquiring the knowledge automatically. Naïve bayesian classifier falls under supervised learning method. Supervised learning method is a form of machine learning in which supervision in learning comes from labeled examples in the training dataset. Supervised learning is also called as ‘Learning with the help of a teacher’ because here class labels are already defined. A naïve bayesian classifier is one of the common techniques for data classification. Classification is a two-step process, one is learning step and another one is classification step. In Learning step, the training set is analyzed for model construction and in classification step, class labels are predicted for the given data based on classification model.
Bayesian classifiers are statistical classifiers. Naïve bayes classifiers are based on the concept of class conditional independence i.e., impact of an attribute value on a given class is independent of the different attributes. These depend on Bayes’ theorem. Bayes theorem uses the concept of posterior probability and prior probability.
Decision tree classifier and random forest: In decision trees, class label is represented by terminal nodes, internal nodes represent the test on an attribute and the outcome of the test is represented by branches of a tree. With the help of decision trees, classification can be easily performed. To predict the class label for a given tuple, the attribute values of the tuple are tested against the decision tree. A path is then traced from root to a leaf node to predict the class for the given tuple. Attribute selection measures are used in decision tree classifier to choose the attribute that best partitions the tuples into particular classes. Most popular attribute selection measures used in decision tree classifier are-Information Gain, Gain Ratio and Gini Index. Decision tree classifiers have gained a lot of popularity because it can handle multidimensional data and it doesn’t require any domain knowledge. In general, decision tree classifiers have good exactness.
Random forests are an ensemble learning technique used for classification. Random forest is a collection of decision trees. It randomly selects the observations and specific features to build multiple decision trees and then results are calculated. In classification problems, the importance of variables is ranked by using random forests. Few of the upsides of random forests is that there is no requirement for pruning of trees and these are not sensitive to outliers in training data. Accuracy and importance of variables are also generated automatically.
Support Vector Machine (SVM): Support vector machines are considered to be most suitable for time series prediction. It can be used both for classification and regression task. The SVM is based on the structural risk minimization principle. This principle prevents the over-fitting problem by incorporating the concept of capacity control. Mathematical programming and Kernel Functions are the two key elements in the implementation of SVM. The SVM comes under supervised learning. Advantages of SVM is that it scales well to high dimensional data. It also reduces the computational cost because the constructed model has dependence only on support vectors. The SVM is considered as a powerful predictive tool for stock market predictions in the financial market.
QUANTITATIVE ANALYSIS OF STOCK MARKET
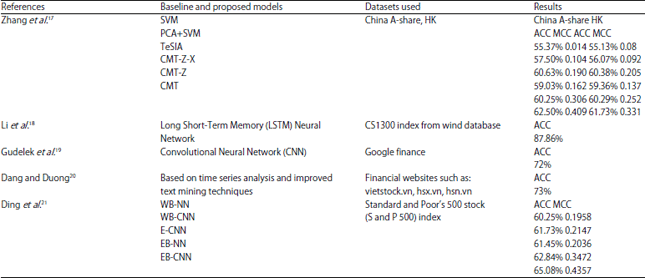
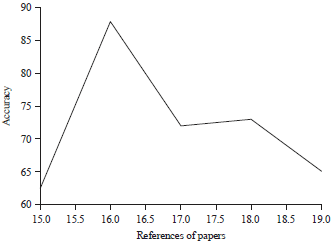
Study of existing literature reviews on the basis of methodologies used for predicting stock market prices, the efficiency of existing methodologies, data sets, and their efficiency are performed. The results shows that the Long Short-Term Memory (LSTM) Neural network has better results in comparison to the Support Vector Machines (SVM), K-Nearest Neighbor (KNN), Principal Component Analysis (PCA), Word embeddings input and convolutional neural network prediction model (WB-CNN), Convolutional Neural Network (CNN) and regression methods. The result in Fig. 1 is a comparative performance efficiency of different techniques cited among the number of research papers in recent years.
| Table 2: | Current papers with their evaluating parameters on respective datasets |
 |
|
 |
|
| Fig. 1: | Comparison of results of recent years |
Table 2 shows the recent papers based on the use of different techniques such as SVM, KNN, PCA, WB-CNN, CNN, and regression methods) along with their efficiency.
Xing et al.6 researchers have used regression analysis method and Hidden Markov Model to predict the future stock prices. They have analyzed both methods and compared their results. Although regression analysis method performs an efficient prediction, it also has great fluctuations. As stock prices change frequently, so fast and accurate prediction is must which cannot be performed with this method. Based on their experimental results, they have proved that the average error of the regression analysis method is more than Hidden Markov Model. So they have concluded that Hidden Markov Model is more efficient than traditional regression analysis method in terms of accuracy because it also takes into consideration hidden variables.
Yetis, et al., have performed stock market prediction by utilizing artificial neural networks. They have typically focused on Multi-Layer Perceptron (MLP) networks. These are feed-forward networks regularly trained with backpropagation. The MLP eases the approximation of the input-output map, so these are widely used for stock market prediction. Naeini et al. has discussed two variants of neural networks i.e., feed-forward multilayer perceptron (MLP) and an Elman recurrent network for stock market prediction. Based on the results, they have concluded that the Elman network predicts the course of changes superior to multilayer perceptron but the Elman recurrent network has a greater error in prediction than MLP. Usmani et al. have tried to predict the stock price by three variants of artificial neural networks i.e. Single Layer Perceptron Model (SLP), Multi-Layer Perceptron Model (MLP), and Radial Basis Function and by Support Vector Machine (SVM) algorithm. Single-layer perceptron is the most basic arrangement which contains an input layer and an output layer. The neurons in the output layer receive the weighted sum of input neurons. Multi-layer perceptron is a feed-forward neural network with one additional layer called a hidden layer radial basis function is also fed forward network and has three layers- input, output, and hidden layer. This function depends on the radial distance from a point. Based on the experimental results they have concluded that SVM performs best on the training set while MLP performs best on the test data set. But the prediction model works best on test data so MLP is considered to be efficient among the others for stock market prediction.
Shubhrata et al. have performed stock market prediction using Naïve Bayes classifier. They have converted the given dataset into a frequency table and then the probabilities of events are calculated. After this, the posterior probabilities of all classes are calculated using Bayes Theorem. Ultimately, a class with the highest posterior probability is the outcome of the prediction. Researchers have concluded that for large data sets, Naïve Bayes classifiers are assumed to be efficient as these are easy to build.
Milosevic predicted the stock price movement by using various algorithms like Decision Trees, Random Forests, Naïve Bayes, etc. and then they compared the accuracy of all algorithms. Based on the experimental results, it was concluded that random forests performed best as compared to other algorithms.
Kumar and Bala, Decision Trees, Random Forests, and Linear Models have been used for stock market prediction. Overall studies and experiments show that random forest is a much better algorithm than the others due to its accuracy.
Support Vector Machine (SVM) and Back Propagation: Techniques (BP) are used by researchers for stock market prediction. They have compared the accuracy of both methods. Based on the experimental results, researchers have concluded that SVM performs better than the BP technique as SVM provides a smaller Normalized Mean Square Error (NMSE), Mean Absolute Error (MAE), and larger directional symmetry (DS) than BPN in most cases because SVM adopts the struc tural risk minimization principle.
Kaushik and Bank proposed an approach for improving reliability in optimal network design and fault-tolerant networks. Results showed that the optimized ANN produces optimal network designs and reliability measures at a reasonable computational cost.
It has summarized the above work of researchers in the form of a table along with the pros and cons of each technique in Table 3.
| Table 3: | Summary of machine learning approaches used |
 |
|
CONCLUSION AND FUTURE SCOPE
In this study, stock market basics are discussed, and then the need for predicting future stock market prices. A few of the approaches which may be used for stock market prediction like Non-linear regression analysis, Hidden Markov Model, Artificial Neural Networks, Naïve Bayes Classifier, Decision Trees Classifier, Random Forest Method, Support Vector Machines, PCA (Principal Component Analysis), WB-CNN (Word embeddings input and convolutional neural network prediction model) and CNN (Convolutional Neural Network) are elaborated in this paper. The results of this research are beneficial in concluding that LSTM (Long Short-Term Memory) Neural network has better results in comparison to other methods.
As a future direction, this research would like to perform a comparative analysis with deep learning classifiers and extreme learning classifiers with the help of a feature reduction algorithm based on the parameters used for stock market prediction. Along with this, the research would also like to study and implement an economic growth model for stock market prediction and the analysis of how the economic growth model will affect stock market prediction in comparison to the linear regression model and with specialized machine learning techniques.